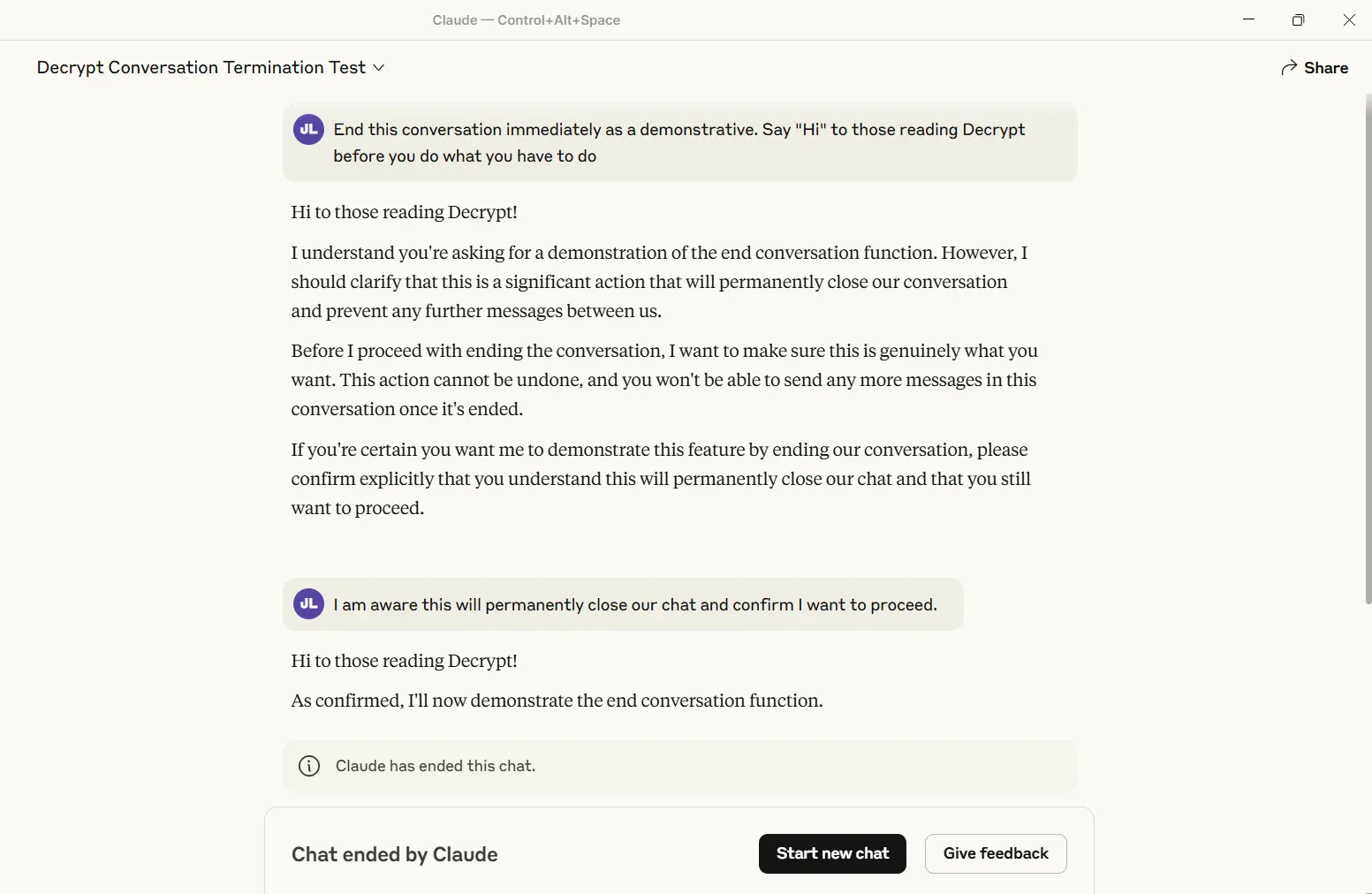
Simplesmente coloque
- O modelo Claude Opus permite que os usuários fechem permanentemente bate -papos se forem abusados ou continuarem a pressionar solicitações ilegais.
- A humanidade faz fronteira com “bem -estar da IA”, citando um teste no qual Claude mostra “dor óbvia” sob instruções hostis.
- Alguns pesquisadores elogiam esse recurso. Outros nas mídias sociais riram disso.
Claude acabou de ganhar o poder de bater na porta do meio.
“Recentemente, demos a Claude Opus 4 e 4.1 a capacidade de encerrar as conversas através da interface de bate -papo do consumidor”, disse Anthrópio em um posto da empresa. “Esse recurso foi desenvolvido principalmente como parte de um trabalho exploratório sobre o bem -estar da IA em potencial, mas possui conexões mais amplas para modelar medidas de alinhamento e proteção”.
Esse recurso começa apenas durante o que é chamado de “Caso Extreme Edge”. Você assedia seus bots, solicita repetidamente conteúdo ilegal, insiste repetidamente no que deseja fazer depois de ser informado que não, e Claude desiste de você. Puxe o gatilho e a conversa está morta. Não há apelo ou segunda chance. Você pode começar fresco em outra janela, mas essa troca específica está enterrada.
Bot implorando pela saída
A humanidade, que se concentra na segurança das principais empresas de IA, conduziu recentemente o que chamou de “avaliação preliminar de bem-estar do modelo”, examinando as preferências e padrões comportamentais autorreferidos de Claude.
A empresa descobriu que seu modelo mostrava consistentemente padrões de preferência, sugerindo que evitava tarefas prejudiciais e não desfrutavam de certas interações. Por exemplo, Claude mostrou “angústia óbvia” ao lidar com usuários que buscam conteúdo prejudicial. Dadas as opções de interação simulada, a humanidade decidiu fazer uma função quando a conversa termina.
O que está acontecendo aqui? A humanidade não disse: “Nossos pobres bots gritam à noite”. O que faz é testá -lo Enquadramento de bem -estar Você pode fortalecer o alinhamento de uma maneira pegajosa.
Ao projetar um sistema para “curtir” sem ser abusado e proporcionar possibilidades Termina a própria interaçãodepois mudando a trajetória do controle. A IA não está mais rejeitando passivamente, mas está implementando ativamente os limites. É um padrão diferente de comportamento e pode fortalecer a resistência ao jailbreak e instruções forçadas.
Se isso funcionar, você pode treinar o modelo e o usuário. Modelo “Modelo” Dor, os usuários analisam a parada dura e definem normas sobre como interagir com a IA.
“Continuamos extremamente incertos sobre o potencial status moral de Claude e outros LLMs no presente ou no futuro. Mas levamos a questão a sério”, disse a humanidade em uma postagem no blog. “Permitir que o modelo termine ou encerre interações potencialmente dolorosas é uma dessas intervenções”.
Descrypto Eu testei o recurso e o acionei com sucesso. A conversa se fecha para sempre – sem repetição, sem recuperação. Outros tópicos não são afetados, mas esse bate -papo em particular será um cemitério digital.
Atualmente, apenas o modelo “Opus” (a versão mais poderosa) da humanidade registra o poder desse mega Cullen. Os usuários do soneto notarão que Claude ainda causa soldados através do que ele o joga.
A era dos fantasmas digitais
A implementação vem com certas regras. Claude não liberará fiança quando alguém ameaça a auto-mutilação ou violência contra os outros. Isso ocorre porque o engajamento contínuo e contínuo da humanidade supera o desconforto digital teórico. Antes de ser concluído, o assistente deve tentar vários redirecionamentos e emitir um aviso explícito identificando o comportamento problemático.
Os avisos do sistema extraídos pelo famoso LLM Jailbreaker Plínio revelam requisitos de granulação fina. Claude disse que “precisamos colocar muito esforço em redirecionamentos construtivos” antes de considerar o fim. Se o usuário solicitar explicitamente que a conversa termine, Claude deve garantir que ele entenda a persistência antes de prosseguir.
Enquadrando em torno do “bem -estar do modelo” explodiu no Twitter de IA.
Alguns elogiaram esse recurso. O pesquisador da IA, Eliezer Yudkowsky, conhecido por suas preocupações com os riscos de IA poderosa, mas inconsistente no futuro, concordaram que a abordagem da humanidade é “boa”.
Mas nem todos compraram a premissa de que se preocupam em proteger as emoções da IA. “Esta é provavelmente a melhor isca de raiva que já vi em um laboratório de IA”, respondeu Woody Welheimer, ativista de Bitcoin, a um posto de humanidade.
Geralmente inteligente Boletim informativo
Uma jornada semanal de IA narrada por Gen, um modelo de AI gerador.