Os pesquisadores chineses de IA conseguiram o que muitas pessoas pensavam que eram antes. É um modelo de código aberto gratuito equivalente ou além do estado do OpenAI -O -OFE -ATROT INFERÊNCIA SISTEMA. Esta é a maneira de tornar isso mais atenção. Assim como os humanos aprendem, foi uma maneira de deixar a AI aprender através de tentativas e erros.
“Deepseek-r1-zero, um modelo treinado por um aprendizado de reforço em larga escala (RL) sem um professor com um professor no estágio anterior, tem uma capacidade de inferência surpreendente”.
“Aprendizagem aprimorada” é um método para dar uma recompensa ao tomar uma boa decisão sem saber qual modelo é e punir uma má decisão. Após uma série de decisões, você aprenderá a seguir o caminho aprimorado pelo resultado.
Primeiro, durante a fase financiada com um professor, o grupo humano fornecerá ao modelo a saída necessária ao modelo e fornecerá ao modelo um contexto para saber o que é bom e o que é bom. Isso leva ao aprendizado reforçado, a próxima fase em que os modelos fornecem uma variedade de resultados e os seres humanos classificam o melhor. Esse processo é repetido muitas vezes até que o modelo reconheça como fornecer consistentemente resultados satisfatórios.
Imagem: Shik profundo
Deepseek R1 é uma direção no desenvolvimento da IA, porque os humanos desempenham um papel mínimo no treinamento. Ao contrário de outros modelos treinados com uma enorme quantidade de dados do professor, o Deepseek R1 aprende principalmente por meio de aprendizado de reforço mecânico. Em outras palavras, você entenderá as coisas essencialmente conduzindo experimentos e obtendo feedback sobre o que funcionará.
“Através da RL, Deepseek-R1-Zero percebe naturalmente muitos movimentos de inferência poderosos e interessantes”, disse ele em seu artigo. Esse modelo também desenvolveu funções avançadas, como auto -verificação e reflexão, mesmo que não seja explicitamente programado.
À medida que o modelo passava pelo processo de treinamento, ele naturalmente aprendeu a atribuir mais “tempo de pensamento” devido a questões complexas, desenvolvendo seus próprios erros. Os pesquisadores enfatizaram o seguinte: “Oh, naquele momento” Aqui, o modelo aprendeu a avaliar a primeira abordagem do problema. Isso não foi explicitamente programado.
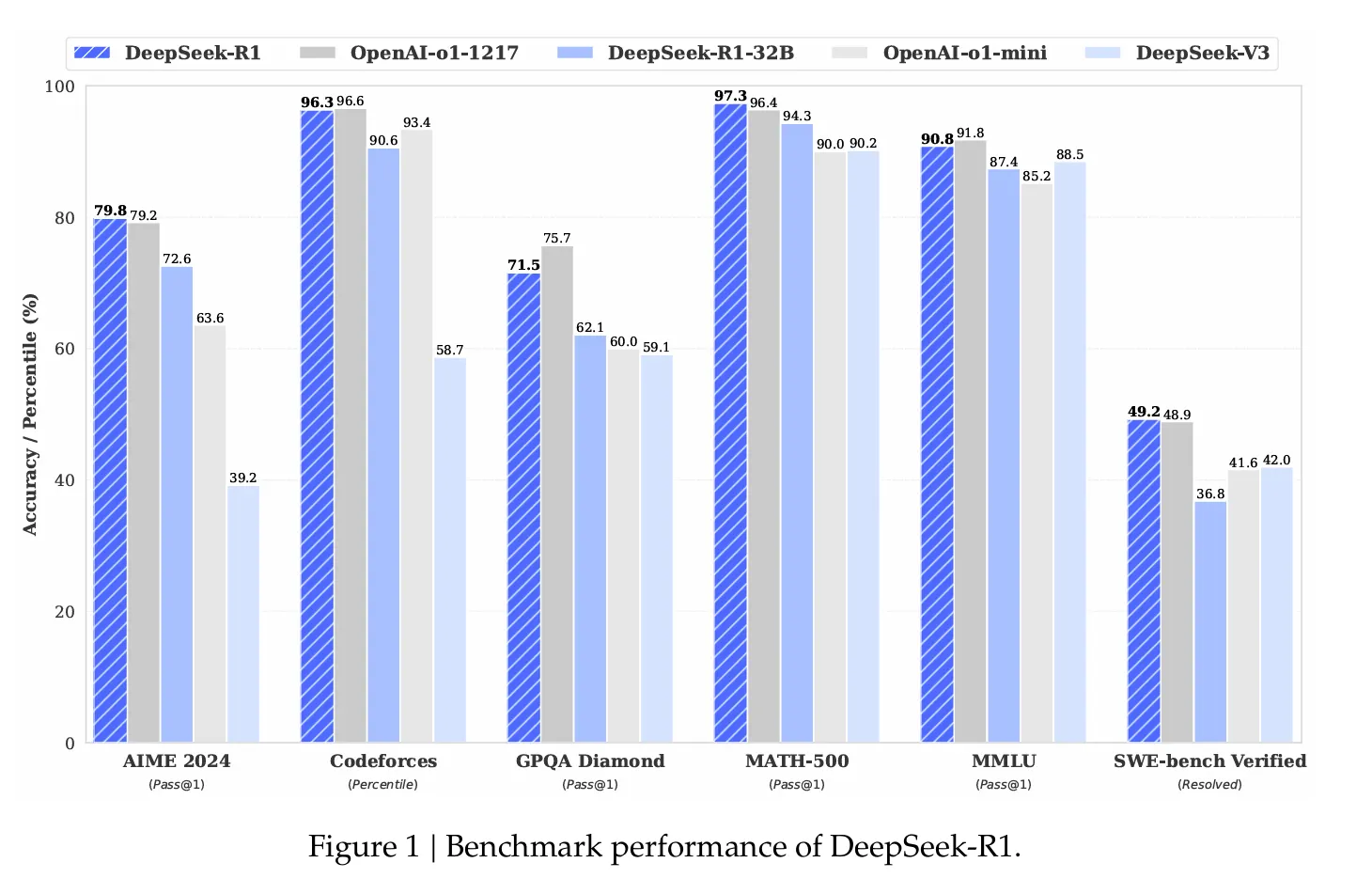
O valor de desempenho é impressionante. Nos benchmarks de matemática do AIME 2024, o Deepseek R1 alcançou uma taxa de sucesso de 79,8% e excedeu o modelo de raciocínio de O1 da O1. O teste de codificação padronizado demonstrou o desempenho do “nível de especialista”, alcançou a avaliação ELO de 2.029 nas forças de código, excedendo 96,3% dos concorrentes humanos.
Imagem: Shik profundo
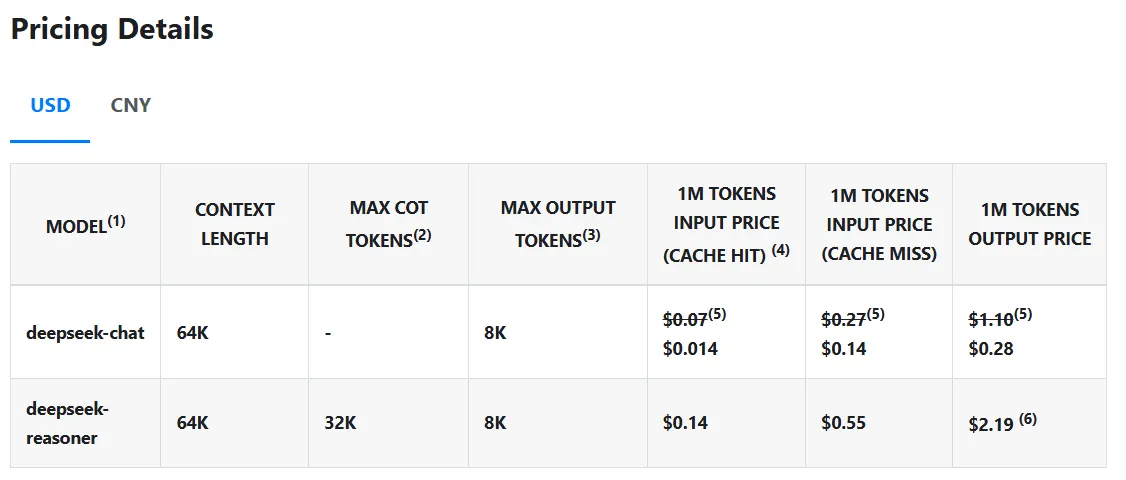
No entanto, é o custo ou o custo do Deepseek R1. Este modelo executa uma consulta por apenas US $ 0,14 por milhão de tokens em comparação com os US $ 7,50 da Openai, o que é 98% mais barato. Ao contrário de um modelo proprietário, o código e o método de treinamento do Deepseek R1 são de código aberto completamente sob a licença do MIT. Em outras palavras, qualquer pessoa pode obter, usar e alterar o modelo sem restrições.
Imagem: Shik profundo
Reação do líder da IA
A liberação do Deepseek R1 causa uma avalanche dos líderes da indústria da IA e muitos enfatizam a importância de um modelo de código aberto completamente, comparável aos seus próprios líderes na função de inferência.
O Dr. Jim Fan, um dos principais pesquisadores da NVIDIA, deu o comentário mais nítido, diretamente semelhante à missão original do Openai. “Estamos vivendo na linha do tempo em que outras empresas que não os Estados Unidos vivem na missão original do Openai, ou seja, uma pesquisa de fronteira verdadeiramente aberta que dá a todas as pessoas”, disse os fãs.
Vivemos na linha do tempo em que as empresas não que não vivem na missão original do Openai, ou seja, pesquisas verdadeiramente abertas e de fronteira. Não faz sentido. O resultado mais interessante é mais provável.
O ventilador revela a importância da abordagem de aprendizado aprimorada do DeepSeek, “Provavelmente, esse é o primeiro projeto (software de código aberto), que mostra o crescimento sustentável significativo dos volantes. curva. “Em contraste com a apresentação do Hype geral na indústria.
Awni Hannun, pesquisadora da Apple, disse que a versão quantizada do modelo pode ser executada localmente no Mac.
O Deepseek R1 671B é executado em dois M2 Ultra e é mais rápido que a velocidade de leitura.
Em casa, aborde a O1, um código aberto sobre hardware de consumo.
Anteriormente, os dispositivos Apple foram considerados vulneráveis à IA porque não são compatíveis com o software CUDA da NVIDIA, mas a situação parece estar mudando. Por exemplo, Alex Chiema, pesquisador de IA, conseguiu executar um modelo completo executando simultaneamente oito Apple Mac Mini. Isso ainda é mais barato que o servidor necessário para executar o modelo de IA mais poderoso atualmente disponível.
No entanto, o usuário pode executar a versão leve do Deepseek R1 no Mac, com um bom nível de precisão e eficiência.
No entanto, a reação mais interessante foi paga para o quão perto a indústria de código aberto está se aproximando de seu próprio modelo e os efeitos potenciais que podem ser pagos ao OpenAI como líder no campo do modelo de IA de inferência.
O fundador da estabilidade da IA, Emado Mostak, adotou uma atitude provocativa e sugeriu que o lançamento pressionasse mais concorrentes financeiros. Ganhar Deep Seek? “
Você pode imaginar se tornar um laboratório “Frontier” que não pode lançar o modelo mais recente porque você não pode vencer o Shik Deep, mesmo que tenha levantado US $ 1 bilhão?
De acordo com a mesma lógica, o empresário de tecnologia Arno Bartrand disse que a aparência de um modelo de código aberto competitivo pode ser potencialmente prejudicial ao OpenAI. Porque esse modelo não é atraente para usuários de energia que gastam dinheiro. Custa muito dinheiro para cada tarefa.
“Em essência, é como vender um telefone celular equivalente ao iPhone, mas vendê -lo por US $ 30 em vez de US $ 1.000. É tão dramático”.
Talvez a maioria das pessoas não entenda o quão más notícias na China são para o Openai.
Eles são comparáveis ao mais recente modelo O1 da OpenAI com vários benchmarks e, mais do que isso, o preço é de apenas 3%.
Arvind Srinivas, CEO da Perplexity AI, explicou esse lançamento da perspectiva do mercado. “Deepseek quase duplicou o O1 Mini e o converte em um código aberto”. “
É um pouco selvagem ver que a inferência é tão rapidamente convertida. É necessário esperar que os modelos de nível O3 sejam abertos no ano até o final do ano e talvez este ano. pic.twitter.com/oyixks4udm
Srinivas disse que sua equipe trabalhará na introdução dos recursos de raciocínio do DeepSeek R1 no Perplexity Pro no futuro.
Prática rápida
A partir desse tipo de pergunta bem conhecida desse tipo de benchmark: “Qual é a palavra Strawberry?”, Fiz alguns testes simples para comparar esse modelo com o OpenAi O1.
Geralmente, os modelos não lidam com palavras, mas para dar uma resposta correta para lidar com tokens, que são expressões digitais de conceitos.
O GPT-4O falhou, mas o OpenAi O1 foi bem-sucedido. O mesmo aconteceu com o Deepseek R1.
No entanto, o O1 teve um processo de raciocínio muito simples, enquanto o Deepseek aplicou uma grande quantidade de saída de raciocínio. Curiosamente, a resposta de Deepseek foi mais humana. Durante o processo de raciocínio, o modelo parecia estar falando apenas usando palavras e palavras de gírias que não são comuns em máquinas, mas mais amplamente utilizadas em humanos.
Por exemplo, o modelo disse a si mesmo: “Ok, vamos pensar sobre isso”, considerando o número de rúpias. Durante a discussão, ele usou “hmm” ou disse: “Espere, não”. Espere e desmonte. “
O modelo acabou chegando ao resultado certo, mas gastou muito tempo para inferência e tokens. Esta é uma desvantagem nas condições gerais de configuração de preços. No entanto, considerando a situação atual, ela pode gerar muito mais tokens do que o OpenAI O1 e ainda manter a competitividade.
Outro teste para verificar a capacidade do modelo foi jogar “espião” e identificar o culpado em um romance curto. Selecione uma amostra no conjunto de dados do GitHub Big Bench. (O texto completo pode ser visto aqui. Isso inclui uma viagem escolar a uma área remota onde a queda de neve está incluída. Os alunos e professores enfrentam uma série de estranhos desaparecimentos, e o modelo deve encontrar quem é o perseguidor. Não).
Eu pensei que os dois modelos por mais de um minuto. No entanto, Chatgpt caiu antes de resolver o mistério.
No entanto, Deepseek deu a resposta correta depois de “pensar” por 106 segundos. O processo de pensamento estava correto e o modelo estava incorreto (mas ainda uma conclusão lógica).
A pequena versão da acessibilidade deu uma boa impressão aos pesquisadores. A propósito, como o modelo 1,5b é muito pequeno, ele pode ser executado teoricamente com um smartphone poderoso. De acordo com o Vaibhav Srivastav, o cientista de dados do rosto abraçando, conseguimos enfrentar o GPT-4o e o claude de 3,5 sonetos em uma versão de quantização R1 tão menor.
“Deepseek-R1-Distill-Qwen-1.5b superou o GPT-4O e o Claude-3,5 no benchmark matemático, alcançados 28,9% na AIME e 83,9% em matemática”.
Apenas uma semana atrás, Skynove, a Universidade da Califórnia, Berkeley, lançou a Sky T1, um modelo de adivinhação que pode competir com a prévia do Openai O1.
Se você estiver interessado em executar o modelo localmente, pode baixá -lo no GitHub ou Huggingf Face. Os usuários podem baixar e executá -los, excluir a censura e multar -os para se adaptar a vários campos especializados.
Ou, se você deseja experimentar o modelo on -line, acesse o bate -papo de abraço ou o Deepseek Web Portal. Esta é uma excelente alternativa ao chatgpt. Em particular, é um código aberto gratuito e é a única interface AI Chat Bot com um modelo construído para inferência além do chatgpt.
Andrew Hayward Editing
Geralmente inteligente Boletim informativo
Uma jornada semanal de IA que Gen, um modelo de IA gerado, fala.